「世論調査の展開と現在」のレジュメの一部
大統領選を外し廃刊に追い込まれた『リテラリ・ダイジェスト』誌
世論調査と聞くと、どれくらいのサンプルを集めれば、信頼に足る世論調査となるのか気になる。井田先生によれば、それを考える上でのひとつの事例が、世論調査について学ぶうえで必ず出てくる1936年のアメリカ大統領選の予測だという。
「1936年のアメリカ大統領選は、民主党で現職のフランクリン・デラノ・ルーズベルトと共和党で新人のアルフレッド・ランドン、両候補で争われました。この選挙予測を行ったのが、雑誌『リテラリ・ダイジェスト』と調査会社のギャラップ社です。『リテラリ・ダイジェスト』誌は大規模な世論調査を行い、ランドンが6:4くらいで現職のルーズベルトに圧勝すると予測しました。しかし結果はみごとに正反対となりルーズベルトが圧勝、『リテラリ・ダイジェスト』誌は廃刊に追い込まれました」
郵送調査を行った1000万人の中身は
予測を外したのはサンプル数が少なかったからではない。『リテラリ・ダイジェスト』誌はじつに1000万人に対して郵送調査を行い、そのうち237万人から回答を得たという。十分すぎるほどの数なのになぜ外したのだろうか。
「問題は、この1000万人の選び方にありました。『リテラリ・ダイジェスト』誌は、自動車保有者名簿、電話保有者名簿、『リテラリ・ダイジェスト』購読者名簿などから1000万人を抽出しました。しかし1936年に車や電話を持っており、『リテラリ・ダイジェスト』という雑誌を読んでいる層は、中流層以上の比較的経済的に恵まれている層です。つまりサンプルに隔たりがあったのです。今でも比較的所得の高い層は小さな政府を志向する共和党を支持する傾向があり、そこからサンプルを抽出すれば共和党に有利に出るのは当たり前でした」
サンプル3000人で大統領選を当てたギャラップ社
「一方、ギャラップ社はその選挙をたった3000人の調査で当てたんです。ギャラップ社が採用したのはクォータ法(割り当て法)でした」
割り当て法とは、有意抽出法ともいい、全体の縮図になるようにサンプルを抽出するものだ。選挙の世論調査でいえば、有権者の票と投票率を掛け合わせて、年代別に何%とあらかじめ割り当てておく。ギャラップはこの割り当て法を採用したのである。
「『リテラリ・ダイジェスト』誌が1000万人で外し、ギャラップ社が3000人で的中させたことで明らかになったことは、調査は10万集めようが1000万集めようが数だけ集めても代表性は保証できない、むしろ数はそんなに多くなくてよいから全体の縮図となるようにサンプリングをしっかりしなければならない、ということでした。このアメリカ的世論調査は近代的世論調査とも言い換えられますし、それは別名、サンプリング重視の世論調査と言うこともできます」
日本でも、政党がインターネットで行う世論調査は割り当て法で行われている。それぞれの年代別にサンプル数を設定しておき、回答するとポイントがたまり、そのサンプル数がいっぱいになると枠がなくなるという仕組みである。
誤差には2種類ある
ではサンプルはいったいどれくらいあればよいのだろうか。ここで考えなければならないのが、〈誤差〉である。
「調査に誤差はつきものです。誤差には2通りあります。1つは〈標本誤差〉。これは全体の一部をサンプルにしていることから生じる誤差。よく±〇%と表されるものですね。もうひとつが〈非標本誤差〉。たとえば調査員が回答をチェックする時書き間違えたり、回答者が設問の内容を取り違えたり、回答漏れがあったり、メイキングといって調査員がノルマを達成するためなどに自分で回答をねつ造したりするものです。こうした〈非標本誤差〉は想定しようがないものなので措いておいて、サンプル数に関係する〈標本誤差〉についてお話ししましょう。
先ほど、数ではなくサンプリングが大事だという話をしましたが、だからといって数が少なすぎると誤差が強く出ます。たとえばコインを投げて表か裏か当てる時、10回より100回、100回より1000回の方が、表か裏が出る確率が理論値である2分の1に近づきます。これが〈大数(たいすう)の法則〉です。また、〈中心極限性定理〉といって、サンプル数が多ければ、そのグラフは正規分布という中心を頂点とした左右対称の釣り鐘型を描きます。これにより〈区間推定〉が理論的に可能になります。
〈区間推定〉というのは、たとえば内閣支持率が43%だとしたとき、誤差が3%あるとされる場合、43%±3%とするものです。それに対して、43%と表すのは〈点推定〉と呼ばれます」
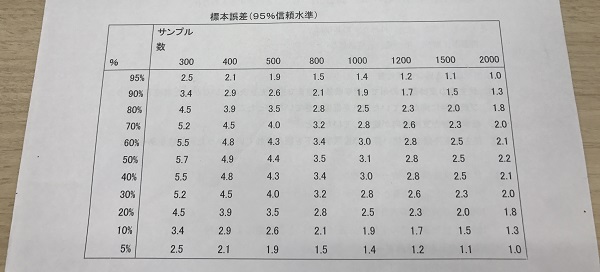
講義で配られたレジュメより「標本誤差(95%信頼水準)」
必要なサンプル数は、標本誤差との関係で決まる
「標本誤差では、正規分布が示す釣り鐘型の山の両裾(両端)のそれぞれ2.5%ずつをカットし、残りの95%の範囲内で区間推定をするのが基準となっています。これを〈95%信頼水準〉と呼んでいます。
上のレジュメの表を見てください。サンプル数300のところを見ると、95%のところに2.5とありますね。これは仮に内閣支持率とした場合、支持率95%の時に誤差が±2.5だということを示します。つまり区間推定92.5~97.5となります。これは支持率5%の場合も同じです。その場合は区間推定2.5%~7.5%となります。こうやって見ていくと、誤差の最大値が50%のところにあることに気づくでしょう。つまり50%の時が最も誤差の範囲が広いのです。たとえばもしサンプル数1000で内閣支持率を調査した時、50%の支持率の時は±3.1%の誤差でも、もし支持率が30%しかなければ誤差は3%ないわけです。
必要なサンプル数は誤差との関係で決まります。400サンプルのところを見ると、50%の誤差が4.9%となります。誤差が±5%に収まればよいといわれていますから、サンプルを最低400集めることはとても重要だとわかります。1000サンプルだと±3.1%、1500だと±2.5%、しかし2000だと±2.1%となり、サンプル数が増えるにつれて誤差の減少幅が少なくなってきます。つまりそれ以上やってもあまり意味がなくなってくるのです。また、サンプルが多ければ多いほどコストがかかりますから、誤差がある程度少なく、コスト的にもよい、1000~1500がサンプル数の一つの基準となります。実際、メディアが行っている内閣支持率等の調査はサンプル数が1000か1500くらいです。
『サンプル数はどれくらいがよいか』とよく聞かれるのですが、最低でも400、できれば1000~1500と答えています」
千代田区長選でも都知事選でもアメリカ大統領選でも、サンプル数は同じでいい
「もうひとつよく訊かれるのが、『有権者数が1000万人を超える東京都知事選と、有権者数4万7000人の千代田区長選では必要なサンプル数が異なるのか』ということです。これがまったく同じなんです。これはアメリカの大統領選でも同じです。つまり、必要なサンプル数に母集団の数はまったく関係がないんです。逆にどんな小さな調査であっても、ある程度の数は必要です。
しかし、サンプル数が数多く必要な場合があります。それが東京都議会議員選挙のような中選挙区での選挙調査の場合です。世田谷区や大田区のような8人区だと、6位・7位・8位・9位あたりの下位では数字が拮抗してきますから、そこを見極めるためにかえってサンプル数は、小選挙区の衆議院選挙よりも必要になってきます」
この標本誤差が影響して、事前予測がひっくり返ったのが、昨年のイギリスのEU離脱の是非を問う国民投票と、アメリカの大統領選だ。これについては次回に記す。
(続く)
◆取材講座:「予測は何を当て、何を外すのか?」第1回「世論調査の展開と現在」(明治大学リバティアカデミー)
〔あわせて読みたい〕
世論調査が安倍氏、前原氏、小池氏を決断させ動かした
現代にも通じる笑えない「ファシズムの兆候」14項目
731部隊は果たして悪魔集団だったのか?
糖尿病になる危険大 避けたい3つの食習慣とは
☆まなナビ☆は、各大学の公開講座が簡単に検索でき、公開講座の内容や講師インタビューが読めるサイトです。トップページの検索窓に「明治大学」と入れたり、気になるジャンルをクリックすると、これから始まる講座が検索できます。
取材・文/まなナビ編集室(土肥元子)